正規化
データベースの設計
ここからは、本格的にデータベースの設計の話について説明していきます。すでに説明したとおり、データベースは、大量のデータへのアクセスを頻繁に行います。そのため、データが某大になりすぎると、アクセススピードが低下するなどといった問題が発生してきます。
そういった問題を最低限におさえ、できるだけ効率的にデータベースへのアクセスをできるように設計する必要があります。そのため、基本となる考え方が、正規化(せいきか)と呼ばれるものです。
正規化とは
では、正規化とは、いったい何でしょう?分かりやすく説明すると、データベースをより効率的なものにするためにテー ブルの設計を考え直す作業のことを言います。具体的には、データの重複をなくし、データの管理を容易にすることにより、データを多様な目的に用いるのに有効な方法のことを指します。
データベースの正規化には第5段階まで存在しますが、リレーショナルデータベースにおいては、一般的に第3正規形にまで準拠していれば良いとされています。その内容は以下の通りです。(表3-1.)
表3-1.データベースの正規化| 状態 | 内容 |
|---|---|
| 非正規化状態 | 全く正規化が行われていない状態のテーブルをいいます。 |
| 第一正規形 | 非正規形のテーブルを、繰り返し現れる列がない状態にしたものです。 |
| 第二正規形 | 主キーとなる列の値が決まれば、他の従属する値が決まるようにテーブルを分割した状態です。 |
| 第三正規形 | 主キーとなる列以外の値によって、他の非主キー列の値が決まることがない状態にテーブルを分割した状態をいいます。 |
では、実際の例を通して、非正規化状態のデータを第三正規形にのテーブルに分割するまでの方法を見てみましょう。
テーブルの正規化
非正規化状態
ここでは、ある会社の社員を管理するテーブルの例をもとに、正規化について考えてみましょう。この会社には、以下のような「社員データカード」があるとします。(表3-2.)
表3-2.社員データカード| データ | 内容 |
|---|---|
| 社員番号 | 20301 |
| 名前 | 山田太郎 |
| 年齢 | 30 |
| 性別ID | 1 |
| 性別 | 男性 |
| 給与 | 324,000円 |
| 保有資格ID | 1,5,7 |
| 保有資格名 | 普通自動車第1種免許,日商簿記一級,中小企業診断士 |
このデータをそのままテーブルにすると次のようになります。これが、非正規化状態のテーブルです。なお、列名などは独自に定義したものです。テーブル名は、employeeとしましょう。(表3-3.)
表3-3.社員データテーブル①(非正規化状態):employee| id | name | age | sex_id | sex | salary | qual_id | qual |
|---|---|---|---|---|---|---|---|
| 2030 | 山田太郎 | 30 | 1 | 男性 | 324,000 | 1 5 7 | 普通自動車第1種免許 日商簿記一級 中小企業診断士 |
第一正規形
非正規化状態のテーブルでは、ひとつのフィールドに複数の値が登録されていました。第一正規形では、まずはこの状態を解消します。(表3-4.)
表3-4.社員データテーブル②(非正規化状態:employee)| id | name | age | sex_id | sex | salary | qual_id | qual |
|---|---|---|---|---|---|---|---|
| 2030 | 山田太郎 | 30 | 1 | 男性 | 324,000 | 1 | 普通自動車第1種免許 |
| 2030 | 山田太郎 | 30 | 1 | 男性 | 324,000 | 5 | 日商簿記一級 |
| 2030 | 山田太郎 | 30 | 1 | 男性 | 324,000 | 7 | 中小企業診断士 |
これでデータベースに登録できるテーブルと同じ形式になりました。しかし、このデータは、重複しているデータが多く存在し、決して効率的とは言えません。
たとえば山田太郎さんの給与が350,000円に変更されたとしたら、合計3つの列に対して変更を加えなければならず、決して効率の良いテーブルではありません。そこで、こういった効率の悪さを改善するために、第二正規形に変更します。
第二正規形
第2正規形では、テーブルの主キーとそれに従属する値の関係にテーブルを分割します。では、具体的にはどのようになるのでしょうか。
先ほどのテーブルでは、id列の値を定めればname、age、salary、sex_id、sex列の値が、idとqual_id列の値を定めればqual列の値が、それぞれ一意に(ひとつに)定まります。(図3-1.)
図3-1.各カラムの関係性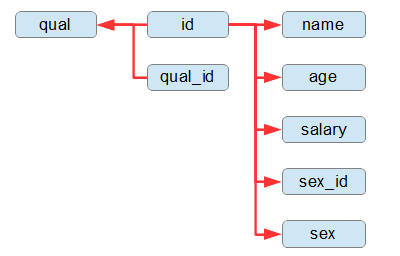 |
そのため、テーブルは、以下のように分割されます。資格に関する情報は、employeeテーブルから分割し、emp_qualというテーブルを作り、そちらに移すことにしましょう。(表3-5.~表3-6.)
表3-5.社員データテーブル③(第二正規形:employee)| id | name | age | sex_id | sex | salary |
|---|---|---|---|---|---|
| 2030 | 山田太郎 | 30 | 1 | 男性 | 324,000 |
| id | qual_id | qual |
|---|---|---|
| 2030 | 1 | 普通自動車第1種免許 |
| 2030 | 5 | 日商簿記一級 |
| 2030 | 7 | 中小企業診断士 |
これで、社員の情報と、資格の情報が分離され、社員の情報を変更する際には、一つのカラムだけを変更すればよい状態になりました。
この状態を解消するのが、第三正規形です。
第三正規形
第三正規形では、主キー以外の値に従属する列をさらにテーブルに分割します。
第二正規形の結果をよく見ると、同じ内容を指す情報が重複しており、無駄が多いことが分かります。employeeテーブルを見ると、性別のIDを表すsex_idと、性別名をあらわすsexは、表現の仕方は異なりますが、同じものを表します。同様に、emp_qualテーブルの、qual_idとqualも同様です。(図3-2.)
図3-2.同一内容を表すデータのカラム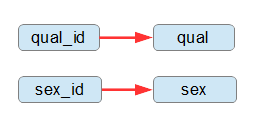 |
これをもとに、さらにテーブルの分割を行うと、以下のようになります。(表3-7.~表3-10.)
表3-7.社員データテーブル④(第三正規形:employee)| id | name | age | sex_id | salary |
|---|---|---|---|---|
| 2030 | 山田太郎 | 30 | 1 | 324,000 |
| id | qual_id |
|---|---|
| 2030 | 1 |
| 2030 | 5 |
| 2030 | 7 |
| sex_id | sex |
|---|---|
| 1 | 男性 |
| qual_id | qual |
|---|---|
| 1 | 普通自動車第1種免許 |
| 5 | 日商簿記一級 |
| 7 | 中小企業診断士 |
第3正規形までの変更を行うと、最初のテーブルは最終的に4つのテーブルに分割されました。これら分割されたテーブルは、SQLの結合処理を行うことで、思い通りの結果セットを取得することができます。
更に、データの変更が起こったときに変えなければいけない箇所が最小にとどめられており、データの不整合が起きにくい仕組みが実現されています。リレーショナルデータベースでは、このような正規化を行ってデータベース内にテーブルを作成していきます。
続いて、この結果をもとに、本格的にデータベースを設計してみることにします。
 |  |  |



